Understanding the Gradient Descent Algorithm for minimizing the cost function of a Linear Regression Model
Gradient Descent is a generic algorithm which is used in many scenarios, apart from finding parameters to minimize a cost function in linear regression. Its a robust algorithm, though a little tricky to implement (as compared to other methods like a Normal Equation method). The generalization of the algorithm applies to univariate and multivariate models to find parameters $\theta_0, \theta_1,\theta_2,.....$ corresponding to the variables $x_0, x_1, x_2... etc$ to minimize the
Cost Function $J_{\theta_0,\theta_1,...}$
More about the Cost Function :
Understanding Linear Regression
Gradient Descent Algorithm :
Case: GD algorithm applied for minimizing $\theta_0 and \theta_1$. The same case can be generalized over multiple values of $\theta$
The Gradient Descent (GD) Algorithm works in the following way:
- Have some function $J(\theta_0,\theta_1)$
- Want to minimize $J_{\theta_0,\theta_1}$
- Outline:
- Start with some value of $\theta_0,\theta_1$
- Keep changing $\theta_0,\theta_1$ to reduce $J(\theta_0,\theta_1)$ until we hopefully end at a minimum
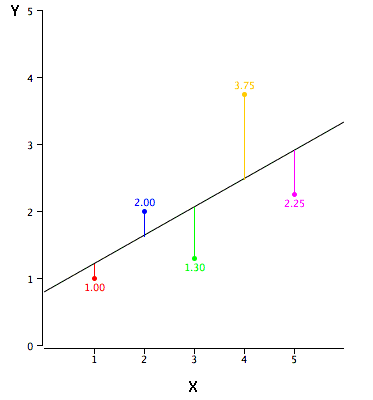
The Gradient Descent starts on a point on the curve generated by plotting $J(\theta_0,\theta_1)$, $\theta_0$ and $\theta_1$. It then takes a small step downwards to find a point where the value of J is lower than the original, and resets $\theta_0$ and $\theta_1$ to the new values. It again takes the step in the downward direction to find a lower cost function J and repeats the steps until we reach the local minima of the curve. The values of $\theta_0$ and $\theta_1$ can be found at this minimum value of J.
Key pointers:
- How do we define how big a step we need to take in the downward direction? This is defined by the parameter $\alpha$ which is called the Learning Rate of the GD algorithm
- The above curve shows there are two local minima. What if the GD algorithm reaches a local minima but the global minima is something else? The reason why GD algorithm works is because the curve in a Linear Regression model is a convex function with only one Global Minima, so irrespective of where you start, you will reach the Global Minima of the function $J(\theta_0,\theta_1)$
Convex function:
Gradient Descent Algorithm: Pseudocode
repeat until convergence $\{$
$\theta_j := \theta_j - {\alpha}{\frac {\partial }{ \partial {\theta_j}}}{J(\theta_0,\theta_1)}$ for j=0 and j=1
$\}$
Simultaneously update both $\theta_0$ and $\theta_1$ i.e. don't plug the value of $\theta_0$ calculated in one step into the function J to calculate the value of $\theta_1$
The Learning Rate $\alpha$: This defines how fast an algorithm converges, i.e. are we taking a small step or a big step in moving to the next minimum value of J. If the value of $\alpha$ is too small, the steps will be small and the algorithm will be slow. If the value of $\alpha$ is large, the steps will be big and we might overshoot the minimum value of J.
Also, as we approach to a global minimum, the GD algorithm will automatically take smaller steps. Thus there is no need to readjust or decrease $\alpha$ over time.
The partial derivative function: This defines the slope of the curve at any given point ($\theta_0,\theta_1$). This could either be negative or positive, and will pull the values of $\theta_0 and \theta_1$ to the minima of the curve.
Application : Gradient Descent Algorithm for Linear Regression
Linear Regression Model: $h_{\theta}(x)={\theta_0}+{\theta_1}(x)$
Cost Function: $J(\theta_0,\theta_1)={\frac{1}{2m}}\sum_{i=1}^m{({h_\theta}(x^{(i)})-y^{(i)})}^2 $
Step 1: Calculate the partial derivatives of J w.r.t. $\theta_0 and \theta_1$
j=0 : ${\frac {\partial}{\partial{\theta_0}}} J_{\theta_0,\theta_1}$ = ${\frac{1}{m}}\sum_{i=1}^m{({h_\theta}(x^{(i)})-y^{(i)})} $
j=1 : ${\frac {\partial}{\partial{\theta_1}}} J_{\theta_0,\theta_1}$ = ${\frac{1}{m}}\sum_{i=1}^m{({h_\theta}(x^{(i)})-y^{(i)})}.{x^{(i)}} $
This is simple partial differentiation, once with $\theta_0$ and again with $\theta_1$, keeping the other parameter constant. If you get it, good, and if you don't get it, it doesn't matter.
Step 2: The Gradient Descent Algorithm now becomes:
repeat until convergence $\{$
$\theta_0 : \theta_0 - \alpha{\frac{1}{m}}\sum_{i=1}^m{({h_\theta}(x^{(i)})-y^{(i)})}$
$\theta_1 : \theta_1-\alpha {\frac{1}{m}}\sum_{i=1}^m{({h_\theta}(x^{(i)})-y^{(i)})}.{x^{(i)}}$
$\}$
Update $\theta_0$ and $\theta_1$ simultaneously
Batch Gradient Descent: Each step of gradient Descent uses all the training examples
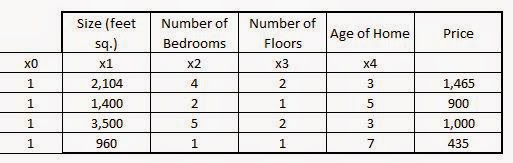
The Normal Equation Method: The exists a method in Linear Algebra where the concept of Metrices and Vectors are used to calculate the parameters $\theta_0$ and $\theta_1$ with iteration. This method is an efficient one, except in the case of very large datasets where it becomes computationally expensive due to the calculation of inverse of very large metrices.
To use the Normal Equation method of solving for $\theta_0$ and $\theta_1$ , the dataset has to be represented in a Matrix format.