Anatomy of a Neuron:
A simgle neuron can be explained by the following system: Dendrites to collect information and transmit information, a cell body as a node/processing unit and Axon as an output wire

We can mimic a simple Logistic Model as a neuron by the following diagram:

The Output function $h_\theta(x)$ is defined by the sigmoid (logistic) activation function $\frac 1 {1+e^{-\theta^Tx}}$
The matrix of weights / parameters is defined by $\theta$ as $\begin{bmatrix}\theta_0 \cr \theta_1 \cr \theta_2 \cr \theta_3 \cr \end{bmatrix}$, the input vector $x$ is defined by $\begin{bmatrix}x_0 \cr x_1 \cr x_2 \cr x_3 \cr \end{bmatrix}$
Sigmoid (logistic) activation function:
$g(z) = \frac 1 {1+e^{-z}}$
The abovementioned representation is for a very simple and basic network with only one hidden layer having only one unit. Typically, a Neural Network has multiple input layer units, multiple hidden layers with multiple units, and multiple output units for multi-class classification.
The input layer has an additiona unit called 'The Bias Unit'($x_0$) which is equal to 1. The activation layers will also have an additional Biad Units equal to one.
Neural Network:

Dimensions of $\Theta^{(j)}$: If the network has $s_j$ units in layer $j$, $s_{j+1}$ units in layer (j+1), then $\Theta^{(j)}$ will be of the dimension $s_{j+1}\times(s_j+1)$
The value of z:
$a_1^{(2)} = g(z_1^{(2)})$
$a_2^{(2)} = g(z_2^{(2)})$
$a_3^{(2)} = g(z_3^{(2)})$
$a_1^{(3)} = g(z^{(3)})$
Forward Propogation Model: Vectorized Implementation:
Define X, $\Theta$, $z_i^j$, $a_i^j$ in a vector notation
$x = \begin{bmatrix}x_0 \cr x_1 \cr x_2 \cr x_3 \cr \end{bmatrix} = \begin{bmatrix}a_0^{(1)} \cr a_1^{(1)} \cr a_2^{(1)} \cr a_3^{(1)}\cr \end{bmatrix}$
$a^{(1)} = x = $$\begin{bmatrix}x_0 \cr x_1 \cr x_2 \cr x_3 \cr \end{bmatrix} = \begin{bmatrix}a_0^{(1)} \cr a_1^{(1)} \cr a_2^{(1)} \cr a_3^{(1)}\cr \end{bmatrix}$
$\Theta^{(1)} = \begin{bmatrix}
\Theta_{10}^{(1)} & \Theta_{11}^{(1)} & \Theta_{12}^{(1)} & \Theta_{13}^{(1)} \cr
\Theta_{20}^{(1)} & \Theta_{21}^{(1)} & \Theta_{22}^{(1)} & \Theta_{23}^{(1)} \cr
\Theta_{30}^{(1)} & \Theta_{31}^{(1)} & \Theta_{32}^{(1)} & \Theta_{33}^{(1)} \cr
\end{bmatrix} \in \Re^{3\times4}$
$z^{(2)} = \Theta^{(1)}a^{(1)}$
$\Theta^{(1)} : 3\times 4$, $a^{(1)} : 4 \times 1$; $z^{(2)} : 3 \times 1$
$a^{(2)} = g(z^{(2)})$, $\in \Re^3$
Add $a_0^{(2)} = 0$ as a bias unit in activation layer (layer 2)
$\Theta^{(2)} = \begin{bmatrix}
\Theta_{10}^{(2)} & \Theta_{11}^{(2)} & \Theta_{12}^{(2)} & \Theta_{13}^{(2)}
\end{bmatrix} \in \Re^{1\times4}$
$z^{(3)} = \Theta^{(2)}a^{(2)}$
$\Theta^{(2)} : 1\times 4$, $a^{(2)} : 4 \times 1$; $z^{(3)} : 1 \times 1$
$h_\Theta(x) = a^{(3)} = g(z^{(3)})$
Neural Network learning its own features: Forward Propagation
This is called a forward propagation because we map the function from layer 1 to layer 2, establish the weight parameters, and then map the function from layer 2 to layer 3. Each layer and parameters $\Theta$ works as an input for the next layer, till it reaches the output layer.
Network Architecture:
A Neural Network can be more complex than the one shown above. A Neural Network can have multiple activation layers $a^{(j)}$, and also multiple output layers.

A simgle neuron can be explained by the following system: Dendrites to collect information and transmit information, a cell body as a node/processing unit and Axon as an output wire

We can mimic a simple Logistic Model as a neuron by the following diagram:

The Output function $h_\theta(x)$ is defined by the sigmoid (logistic) activation function $\frac 1 {1+e^{-\theta^Tx}}$
The matrix of weights / parameters is defined by $\theta$ as $\begin{bmatrix}\theta_0 \cr \theta_1 \cr \theta_2 \cr \theta_3 \cr \end{bmatrix}$, the input vector $x$ is defined by $\begin{bmatrix}x_0 \cr x_1 \cr x_2 \cr x_3 \cr \end{bmatrix}$
Sigmoid (logistic) activation function:
$g(z) = \frac 1 {1+e^{-z}}$
The abovementioned representation is for a very simple and basic network with only one hidden layer having only one unit. Typically, a Neural Network has multiple input layer units, multiple hidden layers with multiple units, and multiple output units for multi-class classification.
The input layer has an additiona unit called 'The Bias Unit'($x_0$) which is equal to 1. The activation layers will also have an additional Biad Units equal to one.
Neural Network:
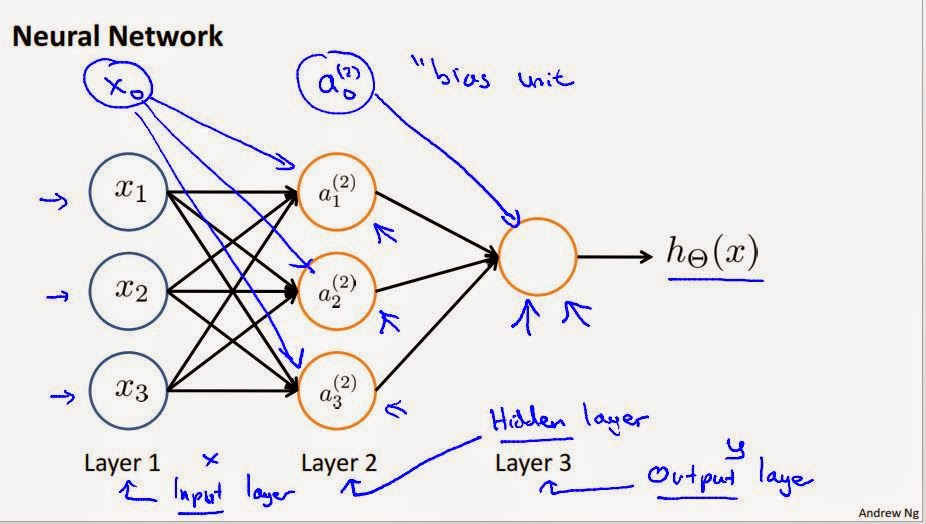
Details:
The Neural Network above consists of three layers : an Input Layer (Layer 1), a Hidden Layer (Layer 2), and an Output Layer (Layer 3). Both the Input and Hidden Layers (Layers 1 and 2) contain a bias unit $x_0$ and $a_0^{(2)}$ respectively.
The Hidden Layer: The Layer 2 or the 'Activation Layer' consists of xxactivation units $a_i^j$ which are defined by weight from the Input Layers. Each Input unit feeds to each Activation unit, and the interaction is characterized by the weight parameters $\theta$.
Number of Units: 4 (including a bias input unit) in Layer 1, 4 (including a bias activation unit) in Layer 2, 1 in Output Layer (Layer 3).
Definitions:
$a_i^{(j)}$: Activation of unit $i$ in layer $(j)$;
$\Theta^{(j)}$: matrix of weights controlling the function mapping from layer $(j)$ to layer $(j+1)$.
$\Theta^{(1)}$ $\in$ $\Re^{3x4}$ : 3 rows for each activation unit $a_1^{(2}), a_2^{(2)}$ and $a_3^{(2)}$. The fourth unit in activation layer $a_0^{(2)}$ is the bias unit equal to 1. The rows 1 to 4 are for the input parameters (including the bias input unit) $x_0, x_1, x_2$ and $x_3$.
The subscript denotes the units (0,1,2, and 3), and the superscript denotes the layer number (1,2 or 3).
$a_1^{(2)}$ denotes the first unit in the second layer.
The sigmoid function $g(z)$ is defined by $g(z) = \frac 1 {1+e^{-z}}$
z is defined as follows:
Layer 2: The activation layer
$a_1^{(2)}=g(\Theta_{10}^{(1)}x_0 + \Theta_{11}^{(1)}x_1 + \Theta_{12}^{(1)}x_2 + \Theta_{13}^{(1)}x_3)$
$a_2^{(2)}=g(\Theta_{20}^{(1)}x_0 + \Theta_{21}^{(1)}x_1 + \Theta_{22}^{(1)}x_2 + \Theta_{23}^{(1)}x_3)$
$a_3^{(2)}=g(\Theta_{30}^{(1)}x_0 + \Theta_{31}^{(1)}x_1 + \Theta_{32}^{(1)}x_2 + \Theta_{33}^{(1)}x_3)$
Layer 3: The output layer
$h_\Theta(x) = a_1^{(3)} = g(\Theta_{10}^{(2)}a_0^{(2)} + \Theta_{11}^{(2)}a_1^{(2)} + \Theta_{12}^{(2)}a_2^{(2)} + \Theta_{13}^{(2)}a_3^{(2)})$
Dimensions of $\Theta^{(j)}$: If the network has $s_j$ units in layer $j$, $s_{j+1}$ units in layer (j+1), then $\Theta^{(j)}$ will be of the dimension $s_{j+1}\times(s_j+1)$
The value of z:
$a_1^{(2)} = g(z_1^{(2)})$
$a_2^{(2)} = g(z_2^{(2)})$
$a_3^{(2)} = g(z_3^{(2)})$
$a_1^{(3)} = g(z^{(3)})$
Forward Propogation Model: Vectorized Implementation:
Define X, $\Theta$, $z_i^j$, $a_i^j$ in a vector notation
$x = \begin{bmatrix}x_0 \cr x_1 \cr x_2 \cr x_3 \cr \end{bmatrix} = \begin{bmatrix}a_0^{(1)} \cr a_1^{(1)} \cr a_2^{(1)} \cr a_3^{(1)}\cr \end{bmatrix}$
$a^{(1)} = x = $$\begin{bmatrix}x_0 \cr x_1 \cr x_2 \cr x_3 \cr \end{bmatrix} = \begin{bmatrix}a_0^{(1)} \cr a_1^{(1)} \cr a_2^{(1)} \cr a_3^{(1)}\cr \end{bmatrix}$
$\Theta^{(1)} = \begin{bmatrix}
\Theta_{10}^{(1)} & \Theta_{11}^{(1)} & \Theta_{12}^{(1)} & \Theta_{13}^{(1)} \cr
\Theta_{20}^{(1)} & \Theta_{21}^{(1)} & \Theta_{22}^{(1)} & \Theta_{23}^{(1)} \cr
\Theta_{30}^{(1)} & \Theta_{31}^{(1)} & \Theta_{32}^{(1)} & \Theta_{33}^{(1)} \cr
\end{bmatrix} \in \Re^{3\times4}$
$z^{(2)} = \Theta^{(1)}a^{(1)}$
$\Theta^{(1)} : 3\times 4$, $a^{(1)} : 4 \times 1$; $z^{(2)} : 3 \times 1$
$a^{(2)} = g(z^{(2)})$, $\in \Re^3$
Add $a_0^{(2)} = 0$ as a bias unit in activation layer (layer 2)
$\Theta^{(2)} = \begin{bmatrix}
\Theta_{10}^{(2)} & \Theta_{11}^{(2)} & \Theta_{12}^{(2)} & \Theta_{13}^{(2)}
\end{bmatrix} \in \Re^{1\times4}$
$z^{(3)} = \Theta^{(2)}a^{(2)}$
$\Theta^{(2)} : 1\times 4$, $a^{(2)} : 4 \times 1$; $z^{(3)} : 1 \times 1$
$h_\Theta(x) = g(\Theta_{10}^{(2)}a_0^{(2)} + \Theta_{11}^{(2)}a_1^{(2)} + \Theta_{12}^{(2)}a_2^{(2)} + \Theta_{13}^{(2)}a_3^{(2)})$
$h_\Theta(x) = a^{(3)} = g(z^{(3)})$
Neural Network learning its own features: Forward Propagation
This is called a forward propagation because we map the function from layer 1 to layer 2, establish the weight parameters, and then map the function from layer 2 to layer 3. Each layer and parameters $\Theta$ works as an input for the next layer, till it reaches the output layer.
Network Architecture:
A Neural Network can be more complex than the one shown above. A Neural Network can have multiple activation layers $a^{(j)}$, and also multiple output layers.

No comments:
Post a Comment