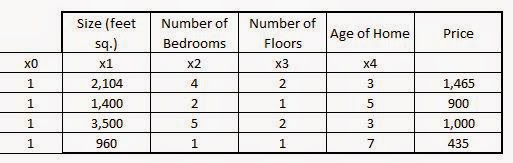
Gradient Computation:
The cost function for a Neural Network: We need to optimize the values of $\Theta$.
$J(\Theta) = -{\frac 1 m} \left[ {\sum_{i=1}^m}{\sum_{k=1}^K}{y_k^{(i)}log(h_\Theta(x)^{(i)})_k}\ +\
{(1-y_k^{(i)})log(1-(h_\Theta(x)^{(i)})_k)}
\right]\ + \
{\frac \lambda {2m}}{\sum_{l=1}^{L-1}}{\sum_{i=1}^{s_l}}{\sum_{j=1}^{s_{l+1}}}
(\Theta_{ji}^{(l)})^2
$
Goal: $min_\Theta \ J(\Theta)$
We need to write the code to compute:
- $J(\Theta)$
- $\frac \partial {\partial\Theta_{ij}^{(l)}} J(\Theta)$
$\Theta_{ij}^l \in \Re$
How to compute the Partial Derivative Terms?
Example : Given One Training Example: Forward Propagation
Given one training example (x,y):
Forward Propagation: Vectorized implementation to calculate the activation values for all layers
$a^{(1)} = x$
$z^{(2)} = \Theta^{(1)}a^{(1)}$
$a^{(2)} = g(z^{(2)}) \ \ (add \ a_0^{(2)})$
$z^{(3)} = \Theta^{(2)}a^{(2)}$
$a^{(3)} = g(z^{(3)})\ \ (add\ a_0^{(3)})$
$z^{(4)} = \Theta^{(3)}a^{(3)}$
$a^{(4)} = h_\Theta(x) = g(z^{(4)})$
Gradient Computation: Backpropagation Algorithm
Intuition : We need to compute $\delta_j^{(l)}$ which is the "error" of node $j$ in layer $l$, or error in the activation values
For each output unit (Layer L=4)
$\delta_j^{(4)} = a_j^{(4)} - y_j$ [$a_j^{(4)} = (h_\Theta(x))_j]$
This $\delta_j^{(4)}$ is essentially the difference between what out hypothesis outputs, and the actual values of y in our training set.
Writing in vectorized format:
$\delta^{(4)} = a^{(4)}-y$
Next step is to compute the values of $\delta$ for other layers.
$\delta^{(3)} = (\Theta^{(3)})^T\delta^{(4)}\ .* g'(z^{(3)})$
$\delta^{(2)} = (\Theta^{(2)})^T\delta^{(3)}\ .* g'(z^{(2)})$
There is no $\delta^{(1)}$ because the first layer correspond to the input units which asre used as such, and there is no error terms associated with it.
$g'()$ is the derivative of the sigmoid activation function.
It can be proved that $g'(z^{(3)}) = a^{(3)} .* (1-a^{(3)})$. Similarily, $g'(z^{(2)}) = a^{(2)} .* (1-a^{(2)})$
Finally, $\frac \partial {\partial\Theta_{ij}^{(l)}} J(\Theta) = a_j^{(l)}\delta_i^{(l+1)}$ (Ignoring $\lambda$; or $\lambda$=0)
Backpropagation Algorithm:
The name Backpropagation comes from the fact that we calculate the $\delta$ terms for the output layer first and then use it to calculate the values of other $\delta$ terms going backward.
Suppose we have a training Set: $\{(x^{(1)},y^{(1)}), (x^{(2)},y^{(2)}),.,.,.,.,(x^{(m)},y^{(m)})\}$
First, set $\Delta_{ij}^{(l)} = 0 $ for all values of $l,i,j$ - This is used to compute $\frac \partial {\partial\Theta_{ij}^{(l)}} J(\Theta)$. Eventually, this $\Delta_{ij}^{(l)}$ will be used to calculate the partial derivative $\frac \partial {\partial\Theta_{ij}^{(l)}} J(\Theta)$. $\Delta_{ij}^{(l)}$ are used as accumulators.
For $i = 1\ to\ m$
Set $a^{(1)} = x^{(i)}$ --> Activation for input layer
Perform Forward Propagation to compute $a^{(l)}$ for $l = 2,3,...L$
Using $y^{(i)}$, compute the error term for the output layer $\delta^{(L)} = a^{(L)}-y^{(i)}$
Use backpropagation algorithm for computing $\delta^{(L-1)}, \delta^{(L-2)}, \delta^{(L-3)},...., \delta^{(2)}$, there is no $\delta^{(1)}$
Finally, $\Delta$ terms are used to accumulate these partial derivatives terms $\Delta^{(l)}_{ij}:= \Delta^{(l)}_{ij} + a_j^{(l)}\delta_i^{(l+1)}$. In vectorized format it can be written as (assuming $\Delta$, $a$ and $\delta$ are all matrices : $\Delta^{(l)}:=\Delta^{(l)} + \delta^{(l+1)}(a^{(l)})^T$
end;
$D_{ij}^{(l)} := {\frac 1 m}\Delta_{ij}^{(l)} + \lambda\Theta_{ij}^{(l)}\ if\ j\ne0$
$D_{ij}^{(l)} := {\frac 1 m}\Delta_{ij}^{(l)} \ \ \ \ \ \ \ \ \ \ \ \ if\ j=0$
Finally, we can calculate the partial derivatives as : $\frac \partial {\partial\Theta_{ij}^{(l)}} J(\Theta) = D_{ij}^{(l)}$
---------------------------------------------------------------------------------
Backpropagation Intuition with Example:
Mechanical steps of Backpropagation Agorithm
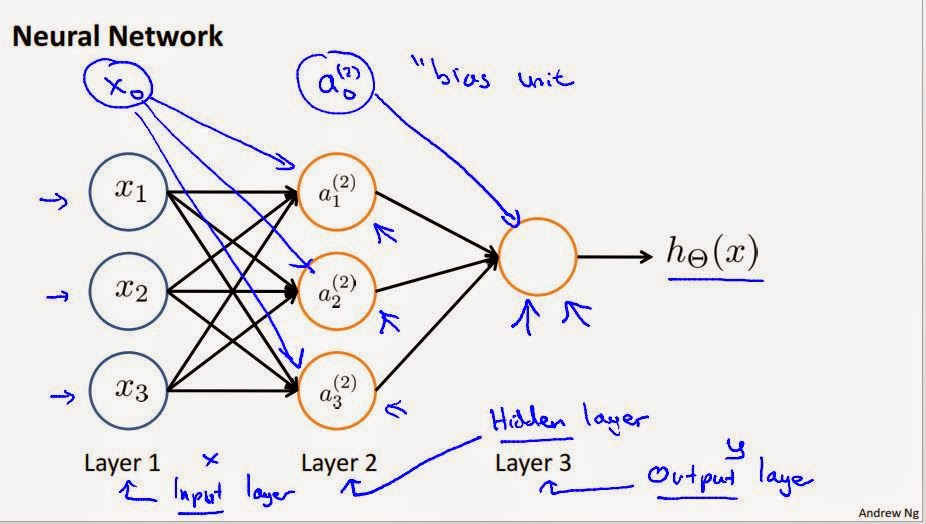
Forward Propagation: Consider a simple NN with 2 input units (not counting the bias unit), 2 activation unit in two layers (not counting bias unit in each layer) and one output unit in layer 4.
The input $(x^{(i)},y^{(i)}$ as represented as below. We first use Forward propagation to compute the values of $z_1^{(2)}$, and apply sigmoid activation function on $z_1^{(2)}$ to get the values of $a_1^{(2)}$. Similarly, the values of $z_2^{(2)}$ and $a_2^{(2)}$ are computed to complete the values of layer 2. The bias unit $a_0^{(2)} = 1$ is added to the layer 2.
Once the values of layer 2 are calculated, we apply the same methodology to compute the values of layer 3 (a & z)
For the values of Layer 3, we have values of $\Theta$ which is use to compute the values of $z_i^{(3)}$.
$z_1^{(3)} = \Theta_{10}^{(2)}a_0^{(2)} + \Theta_{11}^{(2)}a_1^{(2)} + \Theta_{12}^{(2)}a_2^{(2)}$
What is Backpropagation doing? Backpropagation is almost doing the same thing as forward propagation in the opposite direction (right to left, from output to input)
The cost function again:
$J(\Theta) = -{\frac 1 m} \left[ {\sum_{i=1}^m}{\sum_{k=1}^K}{y_k^{(i)}log(h_\Theta(x)^{(i)})_k}\ +\
{(1-y_k^{(i)})log(1-(h_\Theta(x)^{(i)})_k)}
\right]\ + \
{\frac \lambda {2m}}{\sum_{l=1}^{L-1}}{\sum_{i=1}^{s_l}}{\sum_{j=1}^{s_{l+1}}}
(\Theta_{ji}^{(l)})^2
$
Assume $\lambda$ = 0 (remove the regularization term, ignoring for now).
Focusing on single example $x^{(i)},y^{(i)}$, the case of 1 output unit
cost($i$) = $y^{(i)}log\ h_\Theta(x^{(i)}) + (1-y^{(i)})log\ h_\Theta(x^{(i)})$ Cost associated with $x^i,y^i$ training example
Think of $cost (i) \approx (h_\Theta(x^{(i)}) - y^{(i)})^2$ i.e. how well is the network doing on example (i) just for the purpose of intuition,
how close is the output compared to actual observed values y
The $\delta$ terms are actually the partial derivatives of the cost associated with the example (i). They are a measure of how much the weights $\Theta$ needs to be changed to bring the hypothesis output $h_\Theta(x)$ closer to the actual observed value of y.
For the output layer, we first set the value of $\delta_1^{(4)} = y^{(i)}-a_1^{(4)}$.
Next, we calculate the values of $\delta^{(3)}$ in the layer 3 using $\delta^{(4)}$, and the values of $\delta^{(2)}$ in the layer 2 using $\delta^{(3)}$. Please note that there is no $\delta^{(1)}$.
Focusing on calculating the value of $\delta_2^{(2)}$, this is actually the weighted sum (weights being the parameters $\Theta$ and the values of $\delta_1^{(3)}$ and $\delta_2^{(3)}$
$\delta_2^{(2)} = \Theta_{12}^{(2)}\delta_1^{(3)}+ \Theta_{22}^{(2)}\delta_2^{(3)}$
This corresponds to the magenta values + red values in the above diagram
Similarly, to calculate $\delta_2^{(3)}$,
$\delta_2^{(3)} = \Theta_{12}^{(3)}\delta_1^{(4)}$
Once we calculate the values of $\delta$, we can use the optimizer function to calculate the optimized vaues of $\Theta$
















-1.svg.png)